
PDF dokumenty jsou všudypřítomné v obchodních operacích a často vyžadují programový přístup k čtení skenovaného obsahu. Extrakce textu ze skenovaných PDF souborů může být složitá, a proto jsou efektivní nástroje nezbytné. V tomto tutoriálu prozkoumáme jak provádět OCR PDF dokumenty a extrahovat text z PDF v C# pomocí výkonného Aspose.OCR pro .NET API, špičkové knihovny pro extrakci textu z PDF v C# dostupné pro bezplatné hodnocení.
Co se naučíte
V tomto článku se budeme zabývat následujícími tématy:
- Přehled Aspose.OCR pro .NET API
- Kroky k provedení OCR PDF a extrakci textu
- Jak provádět OCR na PDF a uložit text
- Převod OCR PDF na Word
- Převod OCR PDF na JSON
Přehled Aspose.OCR pro .NET API
Využijeme Aspose.OCR pro .NET API, robustní .NET Core PDF OCR řešení. Toto API je navrženo k rozpoznávání textu ze skenovaných obrázků, fotografií z mobilních telefonů a snímků obrazovky, přičemž vrací výsledky v různých formátech dokumentů. Nejen, že převádí obrázky na text, ale také může vytvářet prohledávatelné PDF ze skenů a opravovat překlepy v rozpoznaném textu, což z něj činí jedno z nejrychlejších C# PDF OCR řešení dostupných za pouhých 99 $.
API obsahuje třídu AsposeOcr, která poskytuje více metod pro OCR operace. Zejména metoda RecognizePdf(string, DocumentRecognitionSettings) se používá k extrakci textu ze specifikovaného PDF dokumentu. Třída DocumentRecognitionSettings umožňuje přizpůsobení procesu rozpoznávání, zatímco třída RecognitionResult encapsuluje výsledky rozpoznávání.
Můžete stáhnout DLL API nebo jej nainstalovat pomocí NuGet:
PM> Install-Package Aspose.OCR
Kroky k provedení OCR PDF a extrakci textu v C#
Postupujte podle těchto kroků, abyste provedli OCR na PDF dokumentech a extrahovali rozpoznaný text:
- Vytvořte instanci třídy AsposeOcr.
- Inicializujte objekt třídy DocumentRecognitionSettings.
- Určete jazyk pro OCR.
- Získejte RecognitionResult vyvoláním metody RecognizePdf(), předáním cesty k obrázku a objektu DocumentRecognitionSettings.
- Procházejte seznam RecognitionResult, abyste zobrazili identifikovaný text.
Zde je příklad ilustrující jak provádět OCR PDF dokumenty a extrahovat rozpoznaný text v C#:
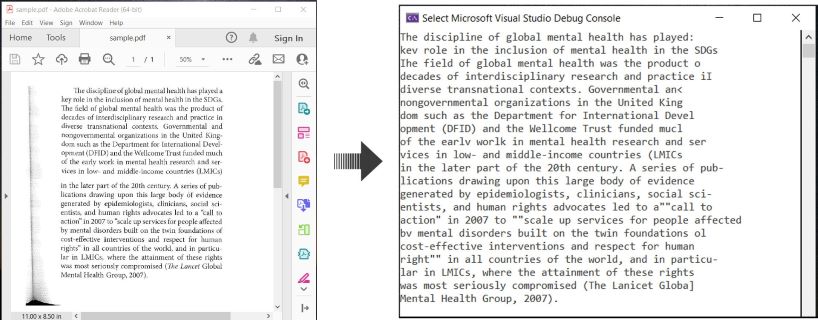
OCR PDF a extrakce textu z PDF v C#
Jak provádět OCR na PDF a uložit text v C#
Chcete-li provádět OCR na PDF dokumentech a uložit rozpoznaný text, postupujte podle těchto kroků:
- Vytvořte instanci třídy AsposeOcr.
- Inicializujte objekt třídy DocumentRecognitionSettings.
- Určete jazyk pro OCR.
- Zavolejte metodu RecognizePdf() k získání RecognitionResult.
- Uložte text pomocí metody SaveMultipageDocument(), která vyžaduje cestu k výstupnímu souboru, SaveFormat a objekt RecognitionResult.
Zde je příklad, který ukazuje jak provádět OCR PDF dokumenty a uložit rozpoznaný text v C#:
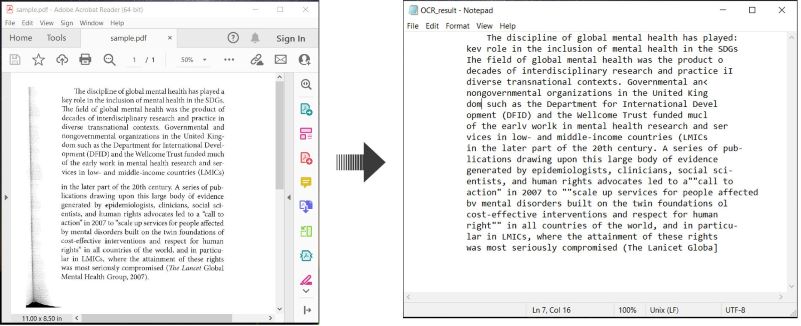
Provést OCR na PDF a uložit text v C#
Převod OCR PDF na Word v C#
Chcete-li převést skenované PDF dokumenty na Word, postupujte podle stejných kroků, jak bylo uvedeno výše, ale v posledním kroku určete SaveFormat.Docx.
Zde je příklad ilustrující jak provádět OCR PDF a uložit rozpoznaný text jako Word dokument v C#:
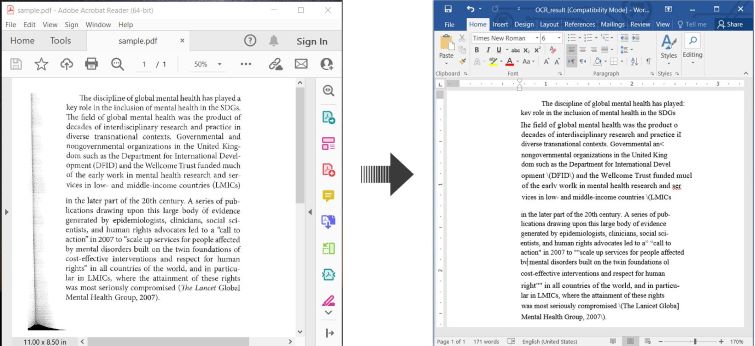
OCR PDF a převod skenovaného PDF na Word v C#
Převod OCR PDF na JSON v C#
Chcete-li uložit rozpoznaný text z PDF dokumentů do JSON souboru, postupujte podle předchozích kroků s tím, že jedinou změnou bude určení SaveFormat.Json v posledním kroku.
Zde je příklad, který ukazuje jak provádět OCR PDF a uložit rozpoznaný text jako JSON soubor v C#:
Získejte bezplatnou hodnotící licenci
Můžete získat bezplatnou dočasnou licenci k hodnocení Aspose.OCR pro .NET API bez jakýchkoliv omezení.
Závěr
V tomto tutoriálu jsme se naučili, jak provádět OCR na PDF dokumentech a extrahovat text z PDF v C#. Také jsme prozkoumali, jak uložit rozpoznaný text jako TXT, DOCX a JSON soubor. Pro více informací o Aspose.OCR pro .NET API se podívejte na jeho dokumentaci. Pokud máte jakékoliv dotazy, neváhejte nás kontaktovat na našem fóru.