
اسناد PDF در عملیات تجاری بسیار متداول هستند و اغلب نیاز به دسترسی برنامهنویسی برای خواندن محتویات اسکن شده دارند. استخراج متن از فایلهای PDF اسکن شده میتواند پیچیده باشد، به همین دلیل ابزارهای مؤثر ضروری هستند. در این آموزش، ما نحوه انجام OCR بر روی اسناد PDF و استخراج متن از PDF در C# با استفاده از Aspose.OCR برای API .NET، یک کتابخانه استخراج متن PDF C# با کیفیت بالا را بررسی خواهیم کرد.
آنچه خواهید آموخت
در این مقاله، ما به بررسی موضوعات زیر خواهیم پرداخت:
- مروری بر Aspose.OCR برای API .NET
- مراحل OCR PDF و استخراج متن
- نحوه انجام OCR بر روی PDF و ذخیره متن
- تبدیل OCR PDF به Word
- تبدیل OCR PDF به JSON
مروری بر Aspose.OCR برای API .NET
ما از Aspose.OCR برای API .NET استفاده خواهیم کرد، یک راهحل OCR PDF قدرتمند .NET Core. این API برای شناسایی متن از تصاویر اسکن شده، عکسهای گوشیهای هوشمند و اسکرینشاتها طراحی شده است و نتایج را در فرمتهای مختلف اسنادی برمیگرداند. این API نه تنها تصاویر را به متن تبدیل میکند، بلکه میتواند از اسکنها PDFهای قابل جستجو ایجاد کند و اشتباهات املایی در متن شناسایی شده را اصلاح کند، که آن را به یکی از سریعترین راهحلهای OCR PDF C# با قیمت فقط 99 دلار تبدیل میکند.
این API شامل کلاس AsposeOcr است که چندین روش برای عملیات OCR ارائه میدهد. بهویژه، روش RecognizePdf(string, DocumentRecognitionSettings) برای استخراج متن از یک سند PDF مشخص استفاده میشود. کلاس DocumentRecognitionSettings امکان سفارشیسازی فرآیند شناسایی را فراهم میکند، در حالی که کلاس RecognitionResult نتایج شناسایی را در بر میگیرد.
شما میتوانید DLL این API را دانلود کنید یا آن را از طریق NuGet نصب کنید:
PM> Install-Package Aspose.OCR
مراحل OCR PDF و استخراج متن در C#
برای انجام OCR بر روی اسناد PDF و استخراج متن شناسایی شده، مراحل زیر را دنبال کنید:
- یک نمونه از کلاس AsposeOcr ایجاد کنید.
- یک شی از کلاس DocumentRecognitionSettings را مقداردهی کنید.
- زبان را برای OCR مشخص کنید.
- با فراخوانی روش RecognizePdf()، RecognitionResult را با عبور از مسیر تصویر و شی DocumentRecognitionSettings به دست آورید.
- در لیست RecognitionResult حلقه بزنید تا متن شناسایی شده را نمایش دهید.
در اینجا یک مثال نشان میدهد چگونه اسناد PDF را OCR کرده و متن شناسایی شده را در C# استخراج کنید:
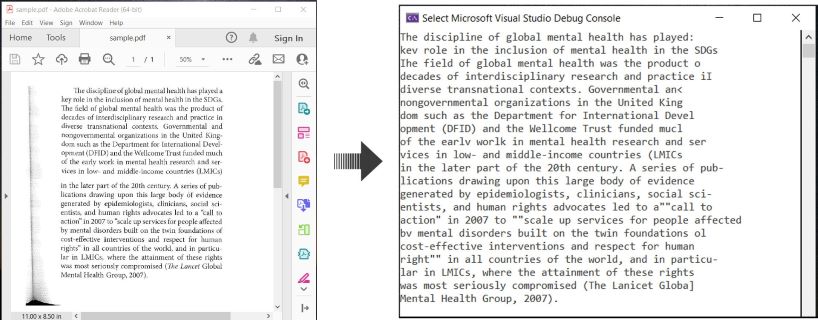
OCR PDF و استخراج متن از PDF در C#
نحوه انجام OCR بر روی PDF و ذخیره متن در C#
برای انجام OCR بر روی اسناد PDF و ذخیره متن شناسایی شده، مراحل زیر را دنبال کنید:
- یک نمونه از کلاس AsposeOcr ایجاد کنید.
- یک شی از کلاس DocumentRecognitionSettings را مقداردهی کنید.
- زبان را برای OCR مشخص کنید.
- با فراخوانی روش RecognizePdf()، RecognitionResult را به دست آورید.
- متن را با استفاده از روش SaveMultipageDocument() ذخیره کنید که نیاز به مسیر فایل خروجی، SaveFormat و شی RecognitionResult دارد.
در اینجا یک مثال نشان میدهد چگونه اسناد PDF را OCR کرده و متن شناسایی شده را در C# ذخیره کنید:
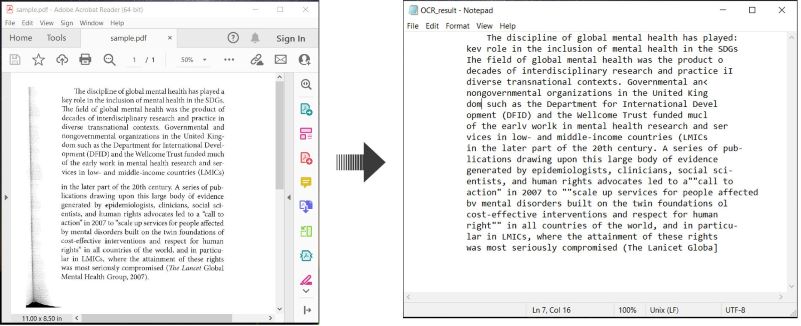
انجام OCR بر روی PDF و ذخیره متن در C#
تبدیل OCR PDF به Word در C#
برای تبدیل اسناد PDF اسکن شده به Word، مراحل قبلی را دنبال کنید، اما در مرحله نهایی SaveFormat.Docx را مشخص کنید.
در اینجا یک مثال نشان میدهد چگونه OCR PDF را انجام داده و متن شناسایی شده را به عنوان یک سند Word در C# ذخیره کنید:
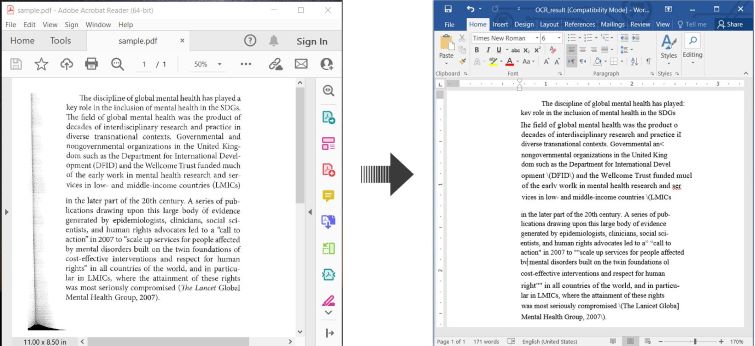
OCR PDF و تبدیل PDF اسکن شده به Word در C#
تبدیل OCR PDF به JSON در C#
برای ذخیره متن شناسایی شده از اسناد PDF در یک فایل JSON، مراحل قبلی را دنبال کنید با این تغییر که در مرحله نهایی SaveFormat.Json را مشخص کنید.
در اینجا یک مثال نشان میدهد چگونه OCR PDF را انجام داده و متن شناسایی شده را به عنوان یک فایل JSON در C# ذخیره کنید:
دریافت مجوز ارزیابی رایگان
شما میتوانید یک مجوز موقت رایگان دریافت کنید تا API Aspose.OCR برای .NET را بدون هیچ محدودیتی ارزیابی کنید.
نتیجهگیری
در این آموزش، یاد گرفتیم که چگونه بر روی اسناد PDF OCR انجام دهیم و متن را از PDF در C# استخراج کنیم. همچنین بررسی کردیم که چگونه متن شناسایی شده را به عنوان یک فایل TXT، DOCX و JSON ذخیره کنیم. برای اطلاعات بیشتر در مورد API Aspose.OCR برای .NET، به مستندات آن مراجعه کنید. اگر سوالی دارید، میتوانید با ما در فروم تماس بگیرید.