
Les documents PDF sont omniprésents dans les opérations commerciales, nécessitant souvent un accès programmatique pour lire le contenu numérisé. L’extraction de texte à partir de fichiers PDF numérisés peut être complexe, c’est pourquoi des outils efficaces sont essentiels. Dans ce tutoriel, nous allons explorer comment réaliser l’OCR sur des documents PDF et extraire du texte d’un PDF en C# en utilisant l’API Aspose.OCR pour .NET, une bibliothèque d’extraction de texte PDF C# de premier plan disponible pour une évaluation gratuite.
Ce que vous apprendrez
Dans cet article, nous aborderons les sujets suivants :
- Aperçu de l’API Aspose.OCR pour .NET
- Étapes pour OCR PDF et Extraire le Texte
- Comment réaliser l’OCR sur un PDF et enregistrer le Texte
- Conversion d’OCR PDF en Word
- Conversion d’OCR PDF en JSON
Aperçu de l’API Aspose.OCR pour .NET
Nous utiliserons l’API Aspose.OCR pour .NET, une solution robuste d’OCR PDF pour .NET Core. Cette API est conçue pour reconnaître le texte à partir d’images numérisées, de photos de smartphone et de captures d’écran, renvoyant les résultats dans divers formats de document. Non seulement elle convertit les images en texte, mais elle peut également créer des PDF recherchables à partir de numérisations tout en corrigeant les fautes d’orthographe dans le texte reconnu, ce qui en fait l’une des solutions OCR PDF C# les plus rapides disponibles pour seulement 99 $.
L’API propose la classe AsposeOcr, qui fournit plusieurs méthodes pour les opérations OCR. Notamment, la méthode RecognizePdf(string, DocumentRecognitionSettings) est utilisée pour extraire du texte d’un document PDF spécifié. La classe DocumentRecognitionSettings permet de personnaliser le processus de reconnaissance, tandis que la classe RecognitionResult encapsule les résultats de la reconnaissance.
Vous pouvez télécharger la DLL de l’API ou l’installer via NuGet:
PM> Install-Package Aspose.OCR
Étapes pour OCR PDF et Extraire le Texte en C#
Suivez ces étapes pour réaliser l’OCR sur des documents PDF et extraire le texte reconnu :
- Créez une instance de la classe AsposeOcr.
- Initialisez un objet de la classe DocumentRecognitionSettings.
- Spécifiez la langue pour l’OCR.
- Obtenez le RecognitionResult en invoquant la méthode RecognizePdf(), en passant le chemin de l’image et l’objet DocumentRecognitionSettings.
- Parcourez la liste RecognitionResult pour afficher le texte identifié.
Voici un exemple illustrant comment réaliser l’OCR sur des documents PDF et extraire le texte reconnu en C# :
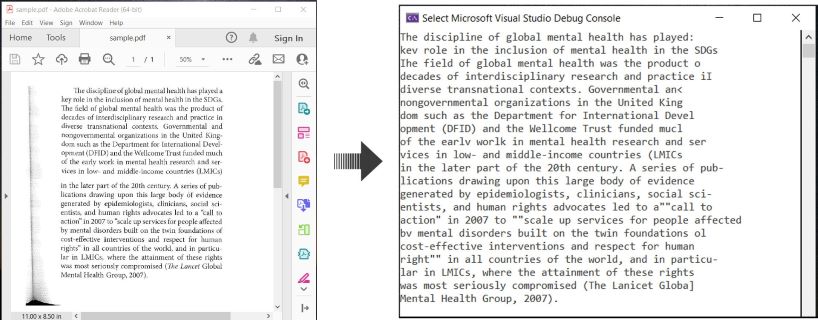
OCR PDF et Extraire le Texte d’un PDF en C#
Comment réaliser l’OCR sur un PDF et enregistrer le Texte en C#
Pour réaliser l’OCR sur des documents PDF et enregistrer le texte reconnu, suivez ces étapes :
- Créez une instance de la classe AsposeOcr.
- Initialisez un objet de la classe DocumentRecognitionSettings.
- Spécifiez la langue pour l’OCR.
- Appelez la méthode RecognizePdf() pour obtenir le RecognitionResult.
- Enregistrez le texte en utilisant la méthode SaveMultipageDocument(), qui nécessite le chemin du fichier de sortie, le SaveFormat, et l’objet RecognitionResult.
Voici un exemple démontrant comment réaliser l’OCR sur des documents PDF et enregistrer le texte reconnu en C# :
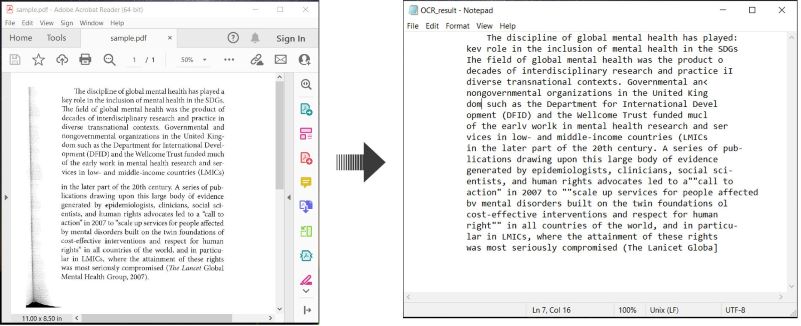
Réaliser l’OCR sur un PDF et Enregistrer le Texte en C#
Conversion d’OCR PDF en Word en C#
Pour convertir des documents PDF numérisés en Word, suivez les mêmes étapes que celles décrites précédemment, mais spécifiez SaveFormat.Docx dans la dernière étape.
Voici un exemple illustrant comment réaliser l’OCR sur un PDF et enregistrer le texte reconnu en tant que document Word en C# :
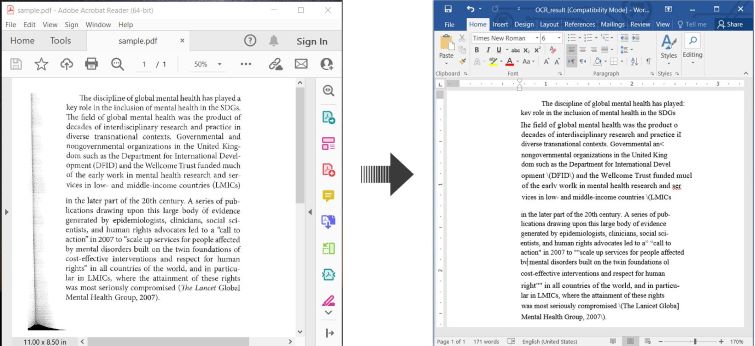
OCR PDF et Convertir un PDF Numérisé en Word en C#
Conversion d’OCR PDF en JSON en C#
Pour enregistrer le texte reconnu à partir de documents PDF dans un fichier JSON, suivez les étapes précédentes en ne changeant que SaveFormat.Json dans la dernière étape.
Voici un exemple démontrant comment réaliser l’OCR sur un PDF et enregistrer le texte reconnu en tant que fichier JSON en C# :
Obtenez une Licence d’Évaluation Gratuite
Vous pouvez obtenir une licence temporaire gratuite pour évaluer l’API Aspose.OCR pour .NET sans aucune limitation.
Conclusion
Dans ce tutoriel, nous avons appris à réaliser l’OCR sur des documents PDF et à extraire du texte d’un PDF en C#. Nous avons également exploré comment enregistrer le texte reconnu sous forme de fichier TXT, DOCX, et JSON. Pour plus d’informations sur l’API Aspose.OCR pour .NET, consultez sa documentation. Si vous avez des questions, n’hésitez pas à nous contacter sur notre forum.