
Dokumen PDF sangat umum dalam operasi bisnis, sering kali memerlukan akses programatis untuk membaca konten yang dipindai. Mengekstrak teks dari file PDF yang dipindai bisa menjadi kompleks, itulah sebabnya alat yang efektif sangat penting. Dalam tutorial ini, kita akan menjelajahi cara melakukan OCR pada dokumen PDF dan mengekstrak teks dari PDF di C# menggunakan Aspose.OCR untuk .NET API, sebuah perpustakaan ekstraksi teks PDF C# terkemuka yang tersedia untuk evaluasi gratis.
Apa yang Akan Anda Pelajari
Dalam artikel ini, kita akan membahas topik berikut:
- Ikhtisar Aspose.OCR untuk .NET API
- Langkah-langkah untuk OCR PDF dan Ekstrak Teks
- Cara Melakukan OCR pada PDF dan Menyimpan Teks
- Mengonversi OCR PDF ke Word
- Mengonversi OCR PDF ke JSON
Ikhtisar Aspose.OCR untuk .NET API
Kita akan memanfaatkan Aspose.OCR untuk .NET API, sebuah solusi PDF OCR .NET Core yang kuat. API ini dirancang untuk mengenali teks dari gambar yang dipindai, foto smartphone, dan tangkapan layar, mengembalikan hasil dalam berbagai format dokumen. Tidak hanya mengonversi gambar menjadi teks, tetapi juga dapat membuat PDF yang dapat dicari dari pemindaian sambil memperbaiki kesalahan ejaan dalam teks yang dikenali, menjadikannya salah satu solusi C# PDF OCR tercepat yang tersedia hanya dengan $99.
API ini memiliki kelas AsposeOcr yang menyediakan berbagai metode untuk operasi OCR. Secara khusus, metode RecognizePdf(string, DocumentRecognitionSettings) digunakan untuk mengekstrak teks dari dokumen PDF yang ditentukan. Kelas DocumentRecognitionSettings memungkinkan untuk kustomisasi proses pengenalan, sementara kelas RecognitionResult mengenkapsulasi hasil pengenalan.
Anda dapat mengunduh DLL dari API atau menginstalnya melalui NuGet:
PM> Install-Package Aspose.OCR
Langkah-langkah untuk OCR PDF dan Ekstrak Teks di C#
Ikuti langkah-langkah ini untuk melakukan OCR pada dokumen PDF dan mengekstrak teks yang dikenali:
- Buat sebuah instance dari kelas AsposeOcr.
- Inisialisasi objek dari kelas DocumentRecognitionSettings.
- Tentukan bahasa untuk OCR.
- Dapatkan RecognitionResult dengan memanggil metode RecognizePdf(), dengan melewatkan jalur gambar dan objek DocumentRecognitionSettings.
- Loop melalui daftar RecognitionResult untuk menampilkan teks yang teridentifikasi.
Berikut adalah contoh yang menggambarkan cara melakukan OCR pada dokumen PDF dan mengekstrak teks yang dikenali di C#:
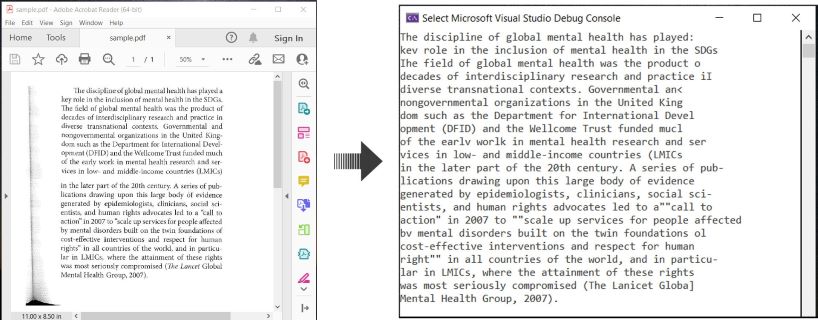
OCR PDF dan Ekstrak Teks dari PDF di C#
Cara Melakukan OCR pada PDF dan Menyimpan Teks di C#
Untuk melakukan OCR pada dokumen PDF dan menyimpan teks yang dikenali, ikuti langkah-langkah ini:
- Buat sebuah instance dari kelas AsposeOcr.
- Inisialisasi objek dari kelas DocumentRecognitionSettings.
- Tentukan bahasa untuk OCR.
- Panggil metode RecognizePdf() untuk mendapatkan RecognitionResult.
- Simpan teks menggunakan metode SaveMultipageDocument(), yang memerlukan jalur file output, SaveFormat, dan objek RecognitionResult.
Berikut adalah contoh yang menunjukkan cara melakukan OCR pada dokumen PDF dan menyimpan teks yang dikenali di C#:
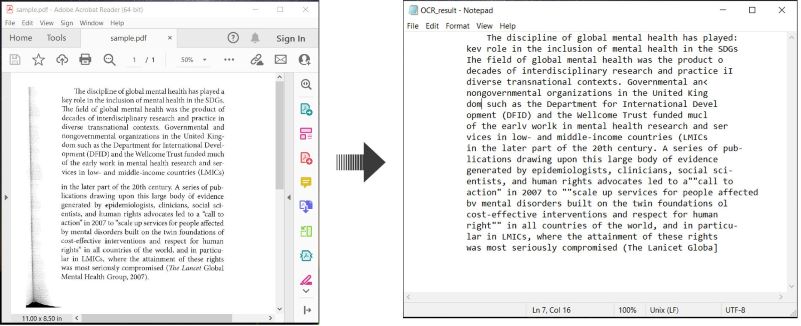
Melakukan OCR pada PDF dan Menyimpan Teks di C#
Mengonversi OCR PDF ke Word di C#
Untuk mengonversi dokumen PDF yang dipindai ke Word, ikuti langkah-langkah yang sama seperti yang diuraikan sebelumnya, tetapi tentukan SaveFormat.Docx di langkah terakhir.
Berikut adalah contoh yang menggambarkan cara melakukan OCR PDF dan menyimpan teks yang dikenali sebagai dokumen Word di C#:
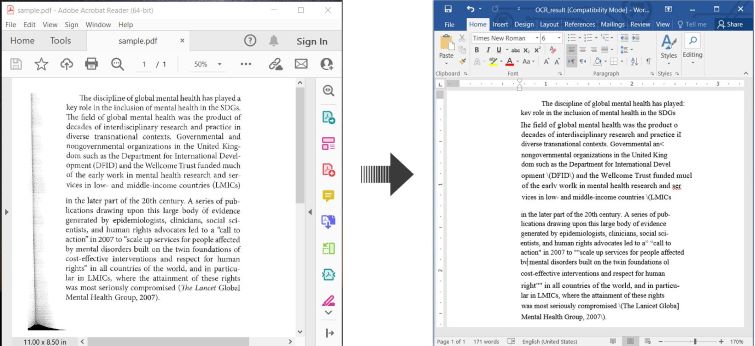
OCR PDF dan Konversi PDF yang Dipindai ke Word di C#
Mengonversi OCR PDF ke JSON di C#
Untuk menyimpan teks yang dikenali dari dokumen PDF dalam file JSON, ikuti langkah-langkah sebelumnya dengan satu-satunya perubahan adalah menentukan SaveFormat.Json di langkah terakhir.
Berikut adalah contoh yang menunjukkan cara melakukan OCR PDF dan menyimpan teks yang dikenali sebagai file JSON di C#:
Dapatkan Lisensi Evaluasi Gratis
Anda dapat mendapatkan lisensi sementara gratis untuk mengevaluasi Aspose.OCR untuk .NET API tanpa batasan.
Kesimpulan
Dalam tutorial ini, kita belajar cara melakukan OCR pada dokumen PDF dan mengekstrak teks dari PDF di C#. Kita juga menjelajahi cara menyimpan teks yang dikenali sebagai file TXT, DOCX, dan JSON. Untuk informasi lebih lanjut tentang Aspose.OCR untuk .NET API, lihat dokumentasinya. Jika Anda memiliki pertanyaan, jangan ragu untuk menghubungi kami di forum kami.