ily"

I documenti PDF sono parte integrante di molti processi aziendali, spesso richiedendo accesso programmatico al loro contenuto scansionato. Estrarre testo da file PDF scansionati può essere complesso, rendendo essenziali strumenti efficaci. In questo tutorial, esploreremo come eseguire OCR su documenti PDF ed estrarre testo da PDF in C# utilizzando il potente Aspose.OCR per .NET API, una delle principali librerie di estrazione di testo PDF in C# disponibile per una valutazione gratuita.
Cosa Imparerai
In questo articolo, tratteremo i seguenti argomenti:
- Panoramica di Aspose.OCR per .NET API
- Passaggi per OCR PDF ed Estrarre Testo
- Come Eseguire OCR su PDF e Salvare Testo
- Conversione di OCR PDF in Word
- Conversione di OCR PDF in JSON
Panoramica di Aspose.OCR per .NET API
Utilizzeremo l’Aspose.OCR per .NET API, una robusta soluzione OCR PDF per .NET Core. Questa API è specificamente progettata per riconoscere testo da immagini scansionate, foto di smartphone e screenshot, restituendo risultati in vari formati di documento. Non solo converte immagini in testo, ma crea anche PDF ricercabili da scansioni e corregge eventuali errori di ortografia nel testo riconosciuto, rendendola una delle soluzioni OCR PDF in C# più veloci disponibili per soli $99.
L’API presenta la classe AsposeOcr, che offre diversi metodi per le operazioni OCR. In particolare, il metodo RecognizePdf(string, DocumentRecognitionSettings) è essenziale per estrarre testo da un documento PDF specificato. La classe DocumentRecognitionSettings consente di personalizzare il processo di riconoscimento, mentre la classe RecognitionResult incapsula i risultati del riconoscimento.
Puoi scaricare il DLL dell’API o installarlo tramite NuGet:
PM> Install-Package Aspose.OCR
Passaggi per OCR PDF ed Estrarre Testo in C#
Per eseguire OCR su documenti PDF ed estrarre il testo riconosciuto, segui questi passaggi:
- Crea un’istanza della classe AsposeOcr.
- Inizializza un oggetto della classe DocumentRecognitionSettings.
- Specifica la lingua per l’OCR.
- Ottieni il RecognitionResult invocando il metodo RecognizePdf(), passando il percorso dell’immagine e l’oggetto DocumentRecognitionSettings.
- Esegui un ciclo attraverso l’elenco RecognitionResult per visualizzare il testo identificato.
Ecco un esempio che illustra come eseguire OCR su documenti PDF ed estrarre testo riconosciuto in C#:
| // This code example demonstrates how to OCR PDF documents and extract the recognized text. | |
| // Initialize the PCR engine | |
| AsposeOcr recognitionEngine = new AsposeOcr(); | |
| // Initialize recognition settings | |
| DocumentRecognitionSettings recognitionSettings = new DocumentRecognitionSettings(); | |
| // Specify language for OCR. Multi-language by default | |
| recognitionSettings.Language = Language.Eng; | |
| // Recognize text from PDF | |
| List<RecognitionResult> results = recognitionEngine.RecognizePdf("C:\\Files\\sample.pdf", recognitionSettings); | |
| // Show the recognized text | |
| foreach (RecognitionResult result in results) | |
| { | |
| Console.WriteLine(result.RecognitionText); | |
| } |
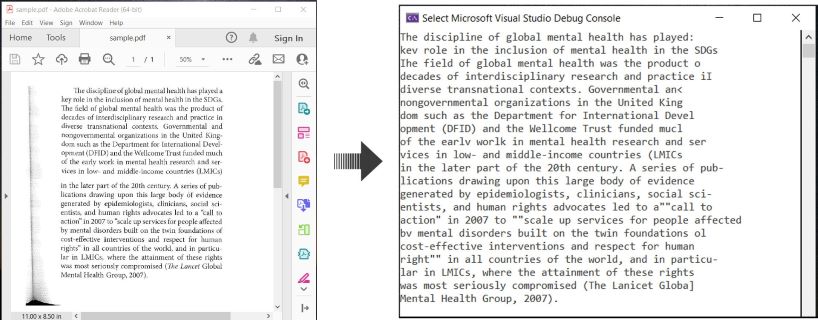
OCR PDF e Estrazione Testo da PDF in C#
Come Eseguire OCR su PDF e Salvare Testo in C#
Per eseguire OCR su documenti PDF e salvare il testo riconosciuto, segui questi passaggi:
- Crea un’istanza della classe AsposeOcr.
- Inizializza un oggetto della classe DocumentRecognitionSettings.
- Specifica la lingua per l’OCR.
- Chiama il metodo RecognizePdf() per ottenere il RecognitionResult.
- Salva il testo utilizzando il metodo SaveMultipageDocument(), che richiede il percorso del file di output, il SaveFormat e l’oggetto RecognitionResult.
Ecco un esempio che dimostra come eseguire OCR su documenti PDF e salvare il testo riconosciuto in C#:
| // This code example demonstrates how to OCR PDF documents and extract the recognized text. | |
| // Initialize the PCR engine | |
| AsposeOcr recognitionEngine = new AsposeOcr(); | |
| // Initialize recognition settings | |
| DocumentRecognitionSettings recognitionSettings = new DocumentRecognitionSettings(); | |
| // Specify language for OCR. Multi-language by default | |
| recognitionSettings.Language = Language.Eng; | |
| // Recognize text from PDF | |
| List<RecognitionResult> results = recognitionEngine.RecognizePdf("C:\\Files\\sample.pdf", recognitionSettings); | |
| // Save the recognized text | |
| AsposeOcr.SaveMultipageDocument("C:\\Files\\OCR_result.txt", SaveFormat.Text, results); |
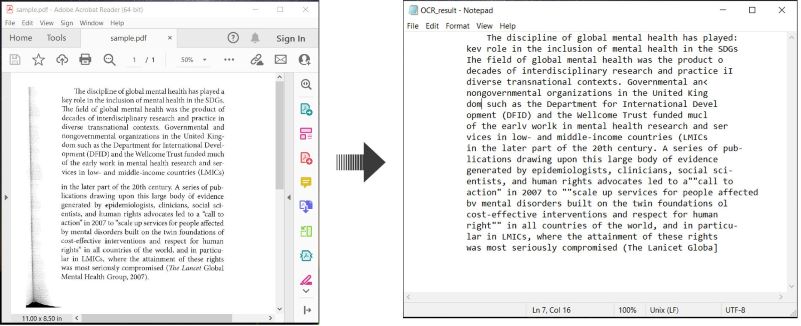
Eseguire OCR su PDF e Salvare Testo in C#
Conversione di OCR PDF in Word in C#
Per convertire documenti PDF scansionati in Word, segui gli stessi passaggi descritti in precedenza, ma specifica SaveFormat.Docx nell’ultimo passaggio.
Ecco un esempio che illustra come eseguire OCR su PDF e salvare il testo riconosciuto come documento Word in C#:
| // This code example demonstrates how to OCR PDF documents and save the recognized text as DOCX. | |
| // Initialize the PCR engine | |
| AsposeOcr recognitionEngine = new AsposeOcr(); | |
| // Initialize recognition settings | |
| DocumentRecognitionSettings recognitionSettings = new DocumentRecognitionSettings(); | |
| // Specify language for OCR. Multi-language by default | |
| recognitionSettings.Language = Language.Eng; | |
| // Recognize text from PDF | |
| List<RecognitionResult> results = recognitionEngine.RecognizePdf("C:\\Files\\sample.pdf", recognitionSettings); | |
| // Save the recognized text as DOCX | |
| AsposeOcr.SaveMultipageDocument("C:\\Files\\OCR_result.docx", SaveFormat.Docx, results); |
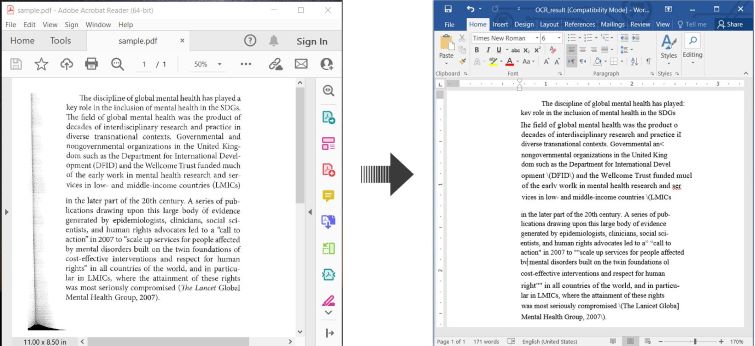
OCR PDF e Convertire PDF Scansionati in Word in C#
Conversione di OCR PDF in JSON in C#
Per salvare il testo riconosciuto da documenti PDF in un file JSON, segui i passaggi precedenti con l’unica modifica di specificare SaveFormat.Json nell’ultimo passaggio.
Ecco un esempio che dimostra come eseguire OCR su PDF e salvare il testo riconosciuto come file JSON in C#:
| // This code example demonstrates how to OCR PDF documents and save the recognized text as JSON. | |
| // Initialize the PCR engine | |
| AsposeOcr recognitionEngine = new AsposeOcr(); | |
| // Initialize recognition settings | |
| DocumentRecognitionSettings recognitionSettings = new DocumentRecognitionSettings(); | |
| // Specify language for OCR. Multi-language by default | |
| recognitionSettings.Language = Language.Eng; | |
| // Recognize text from PDF | |
| List<RecognitionResult> results = recognitionEngine.RecognizePdf("C:\\Files\\sample.pdf", recognitionSettings); | |
| // Save the recognized text as JSON | |
| AsposeOcr.SaveMultipageDocument("C:\\Files\\OCR_result.json", SaveFormat.Json, results); |
Ottieni una Licenza di Valutazione Gratuita
Puoi ottenere una licenza temporanea gratuita per valutare l’Aspose.OCR per .NET API senza limitazioni.
Conclusione
In questo tutorial, abbiamo imparato come eseguire OCR su documenti PDF ed estrarre testo da PDF in C#. Abbiamo anche esplorato come salvare il testo riconosciuto come file TXT, DOCX e JSON. Per ulteriori informazioni sull’Aspose.OCR per .NET API, consulta la sua documentazione. Se hai domande, non esitare a contattarci sul nostro forum.