
PDF 문서는 비즈니스 운영에서 널리 사용되며, 스캔한 내용을 읽기 위해 프로그래밍 방식의 접근이 종종 필요합니다. 스캔한 PDF 파일에서 텍스트를 추출하는 것은 복잡할 수 있으므로 효과적인 도구가 필수적입니다. 이 튜토리얼에서는 강력한 Aspose.OCR for .NET API를 사용하여 C#에서 PDF 문서의 OCR 및 PDF에서 텍스트를 추출하는 방법을 살펴보겠습니다. 이 API는 무료 평가판으로 제공되는 최고급 C# PDF 텍스트 추출 라이브러리입니다.
배울 내용
이 기사에서는 다음 주제를 다룹니다:
- Aspose.OCR for .NET API 개요
- PDF OCR 및 텍스트 추출 단계
- PDF에서 OCR 수행 및 텍스트 저장하기
- OCR PDF를 Word로 변환하기
- OCR PDF를 JSON으로 변환하기
Aspose.OCR for .NET API 개요
우리는 강력한 .NET Core PDF OCR 솔루션인 Aspose.OCR for .NET API를 사용할 것입니다. 이 API는 스캔한 이미지, 스마트폰 사진 및 스크린샷에서 텍스트를 인식하도록 설계되었으며, 다양한 문서 형식으로 결과를 반환합니다. 이미지를 텍스트로 변환할 뿐만 아니라 스캔에서 검색 가능한 PDF를 생성하고 인식된 텍스트의 철자 오류를 수정할 수 있어, 단 $99에 제공되는 가장 빠른 C# PDF OCR 솔루션 중 하나입니다.
API는 OCR 작업을 위한 여러 메서드를 제공하는 AsposeOcr 클래스를 특징으로 합니다. 특히, 지정된 PDF 문서에서 텍스트를 추출하는 데 사용되는 RecognizePdf(string, DocumentRecognitionSettings) 메서드가 있습니다. DocumentRecognitionSettings 클래스는 인식 프로세스를 사용자 정의할 수 있게 해주며, RecognitionResult 클래스는 인식 결과를 캡슐화합니다.
API의 DLL을 다운로드하거나 NuGet을 통해 설치할 수 있습니다:
PM> Install-Package Aspose.OCR
PDF OCR 및 텍스트 추출 단계
PDF 문서에서 OCR을 수행하고 인식된 텍스트를 추출하려면 다음 단계를 따르십시오:
- AsposeOcr 클래스의 인스턴스를 생성합니다.
- DocumentRecognitionSettings 클래스의 객체를 초기화합니다.
- OCR 언어를 지정합니다.
- 이미지 경로와 DocumentRecognitionSettings 객체를 전달하여 RecognizePdf() 메서드를 호출하여 RecognitionResult를 얻습니다.
- 인식된 텍스트를 표시하기 위해 RecognitionResult 목록을 반복합니다.
다음은 C#에서 PDF 문서의 OCR 및 인식된 텍스트 추출 방법을 설명하는 예입니다:
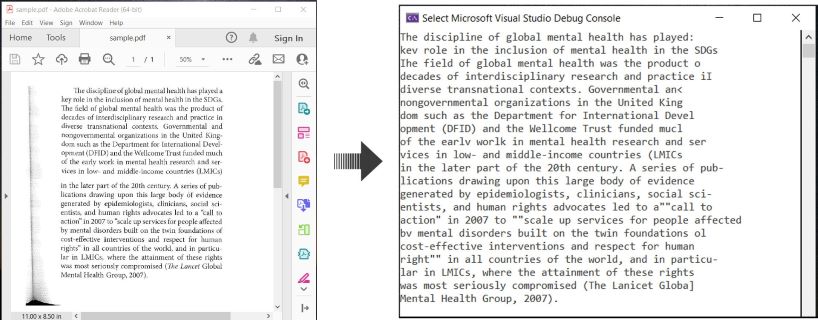
C#에서 OCR PDF 및 PDF에서 텍스트 추출하기
PDF에서 OCR 수행 및 텍스트 저장하기
PDF 문서에서 OCR을 수행하고 인식된 텍스트를 저장하려면 다음 단계를 따르십시오:
- AsposeOcr 클래스의 인스턴스를 생성합니다.
- DocumentRecognitionSettings 클래스의 객체를 초기화합니다.
- OCR 언어를 지정합니다.
- RecognizePdf() 메서드를 호출하여 RecognitionResult를 얻습니다.
- 출력 파일 경로, SaveFormat, RecognitionResult 객체를 요구하는 SaveMultipageDocument() 메서드를 사용하여 텍스트를 저장합니다.
다음은 C#에서 PDF 문서의 OCR 및 인식된 텍스트 저장 방법을 설명하는 예입니다:
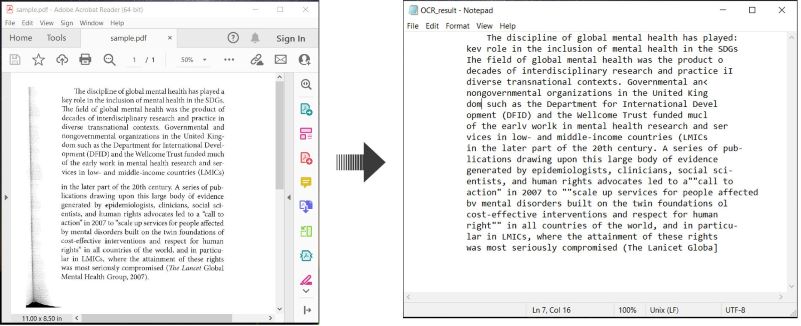
PDF에서 OCR 수행 및 텍스트 저장하기
OCR PDF를 Word로 변환하기
스캔한 PDF 문서를 Word로 변환하려면 앞서 설명한 단계를 따르되, 마지막 단계에서 SaveFormat.Docx를 지정하십시오.
다음은 C#에서 OCR PDF 및 인식된 텍스트를 Word 문서로 저장하는 방법을 설명하는 예입니다:
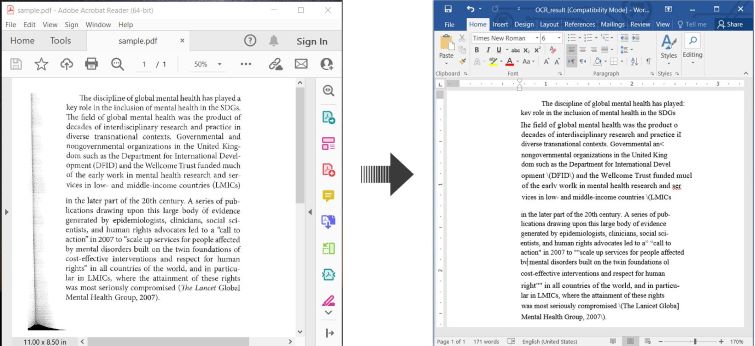
C#에서 OCR PDF 및 스캔한 PDF를 Word로 변환하기
OCR PDF를 JSON으로 변환하기
PDF 문서에서 인식된 텍스트를 JSON 파일로 저장하려면 이전 단계를 따르되, 마지막 단계에서 SaveFormat.Json을 지정하십시오.
다음은 C#에서 OCR PDF 및 인식된 텍스트를 JSON 파일로 저장하는 방법을 설명하는 예입니다:
무료 평가 라이선스 받기
제한 없이 Aspose.OCR for .NET API를 평가할 수 있는 무료 임시 라이선스를 받을 수 있습니다.
결론
이 튜토리얼에서는 PDF 문서에서 OCR을 수행하고 C#에서 PDF에서 텍스트를 추출하는 방법을 배웠습니다. 또한 인식된 텍스트를 TXT, DOCX, JSON 파일로 저장하는 방법을 살펴보았습니다. Aspose.OCR for .NET API에 대한 더 많은 정보는 문서를 확인하십시오. 질문이 있는 경우 포럼에서 문의해 주십시오.