
PDF documents are ubiquitous in business operations, often requiring programmatic access to read scanned content. Extracting text from scanned PDF files can be complex, which is why effective tools are essential. In this tutorial, we will explore how to OCR PDF documents and extract text from PDF in C# using the powerful Aspose.OCR for .NET API, a top-tier C# PDF text extraction library available for free evaluation.
What You Will Learn
In this article, we will cover the following topics:
- Overview of Aspose.OCR for .NET API
- Steps to OCR PDF and Extract Text
- How to Perform OCR on PDF and Save Text
- Converting OCR PDF to Word
- Converting OCR PDF to JSON
Overview of Aspose.OCR for .NET API
We will utilize the Aspose.OCR for .NET API, a robust .NET Core PDF OCR solution. This API is designed to recognize text from scanned images, smartphone photos, and screenshots, returning results in various document formats. Not only does it convert images to text, but it can also create searchable PDFs from scans while correcting spelling mistakes in the recognized text, making it one of the fastest C# PDF OCR solutions available for just $99.
The API features the AsposeOcr class, which provides multiple methods for OCR operations. Notably, the RecognizePdf(string, DocumentRecognitionSettings) method is used to extract text from a specified PDF document. The DocumentRecognitionSettings class allows for customization of the recognition process, while the RecognitionResult class encapsulates the results of the recognition.
You can download the DLL of the API or install it via NuGet:
PM> Install-Package Aspose.OCR
Steps to OCR PDF and Extract Text in C#
Follow these steps to perform OCR on PDF documents and extract the recognized text:
- Create an instance of the AsposeOcr class.
- Initialize an object of the DocumentRecognitionSettings class.
- Specify the language for OCR.
- Obtain the RecognitionResult by invoking the RecognizePdf() method, passing the image path and the DocumentRecognitionSettings object.
- Loop through the RecognitionResult list to display the identified text.
Here’s an example illustrating how to OCR PDF documents and extract recognized text in C#:
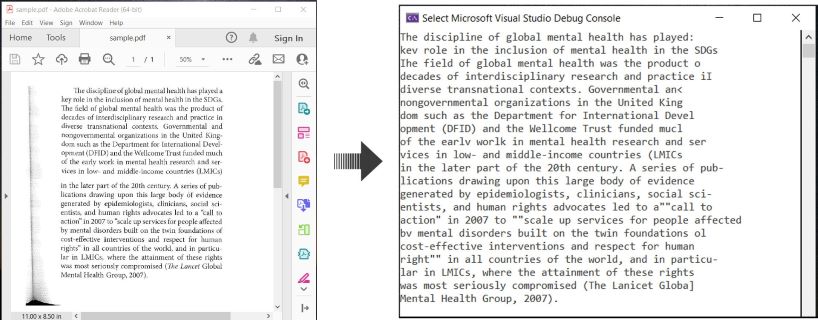
OCR PDF and Extract Text from PDF in C#
How to Perform OCR on PDF and Save Text in C#
To perform OCR on PDF documents and save the recognized text, follow these steps:
- Create an instance of the AsposeOcr class.
- Initialize an object of the DocumentRecognitionSettings class.
- Specify the language for OCR.
- Call the RecognizePdf() method to obtain the RecognitionResult.
- Save the text using the SaveMultipageDocument() method, which requires the output file path, the SaveFormat, and the RecognitionResult object.
Here’s an example demonstrating how to OCR PDF documents and save the recognized text in C#:
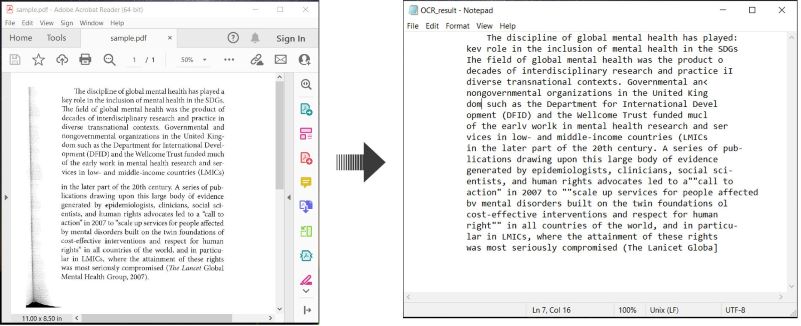
Perform OCR on PDF and Save Text in C#
Converting OCR PDF to Word in C#
To convert scanned PDF documents to Word, follow the same steps as outlined earlier, but specify SaveFormat.Docx in the final step.
Here’s an example illustrating how to OCR PDF and save the recognized text as a Word document in C#:
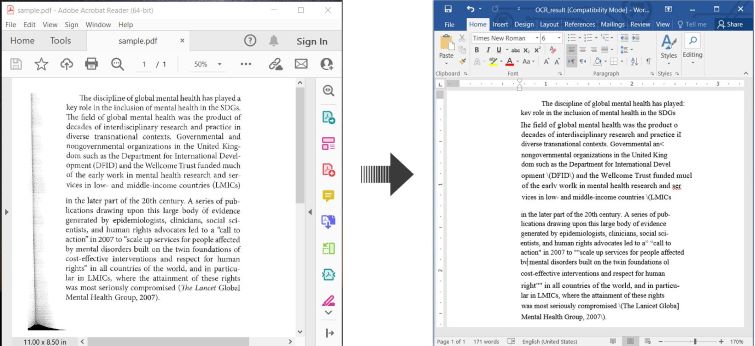
OCR PDF and Convert Scanned PDF to Word in C#
Converting OCR PDF to JSON in C#
To save recognized text from PDF documents in a JSON file, follow the previous steps with the only change being to specify SaveFormat.Json in the final step.
Here’s an example demonstrating how to OCR PDF and save the recognized text as a JSON file in C#:
Get a Free Evaluation License
You can obtain a free temporary license to evaluate the Aspose.OCR for .NET API without any limitations.
Conclusion
In this tutorial, we learned how to perform OCR on PDF documents and extract text from PDF in C#. We also explored how to save the recognized text as a TXT, DOCX, and JSON file. For more information on the Aspose.OCR for .NET API, check out its documentation. If you have any questions, feel free to reach out to us on our forum.