
Documentos PDF são onipresentes nas operações comerciais, frequentemente exigindo acesso programático para ler conteúdo digitalizado. Extrair texto de arquivos PDF digitalizados pode ser complexo, por isso ferramentas eficazes são essenciais. Neste tutorial, vamos explorar como fazer OCR em documentos PDF e extrair texto de PDF em C# usando a poderosa Aspose.OCR para API .NET, uma biblioteca de extração de texto PDF C# de primeira linha disponível para avaliação gratuita.
O Que Você Vai Aprender
Neste artigo, cobriremos os seguintes tópicos:
- Visão Geral da Aspose.OCR para API .NET
- Passos para Fazer OCR em PDF e Extrair Texto
- Como Realizar OCR em PDF e Salvar Texto
- Convertendo OCR PDF para Word
- Convertendo OCR PDF para JSON
Visão Geral da Aspose.OCR para API .NET
Utilizaremos a Aspose.OCR para API .NET, uma robusta solução de OCR PDF para .NET Core. Esta API é projetada para reconhecer texto a partir de imagens digitalizadas, fotos de smartphones e capturas de tela, retornando resultados em vários formatos de documento. Não apenas converte imagens em texto, mas também pode criar PDFs pesquisáveis a partir de digitalizações, corrigindo erros de ortografia no texto reconhecido, tornando-se uma das soluções de OCR PDF C# mais rápidas disponíveis por apenas $99.
A API apresenta a classe AsposeOcr, que fornece vários métodos para operações de OCR. Notavelmente, o método RecognizePdf(string, DocumentRecognitionSettings) é usado para extrair texto de um documento PDF especificado. A classe DocumentRecognitionSettings permite a personalização do processo de reconhecimento, enquanto a classe RecognitionResult encapsula os resultados do reconhecimento.
Você pode baixar a DLL da API ou instalá-la via NuGet:
PM> Install-Package Aspose.OCR
Passos para Fazer OCR em PDF e Extrair Texto em C#
Siga estes passos para realizar OCR em documentos PDF e extrair o texto reconhecido:
- Crie uma instância da classe AsposeOcr.
- Inicialize um objeto da classe DocumentRecognitionSettings.
- Especifique o idioma para OCR.
- Obtenha o RecognitionResult invocando o método RecognizePdf(), passando o caminho da imagem e o objeto DocumentRecognitionSettings.
- Percorra a lista RecognitionResult para exibir o texto identificado.
Aqui está um exemplo ilustrando como fazer OCR em documentos PDF e extrair texto reconhecido em C#:
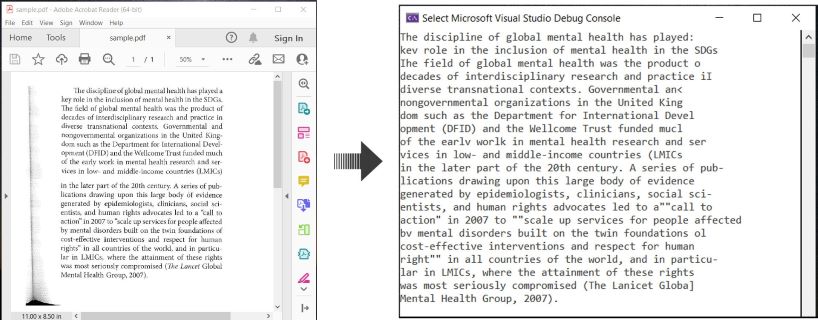
OCR PDF e Extrair Texto de PDF em C#
Como Realizar OCR em PDF e Salvar Texto em C#
Para realizar OCR em documentos PDF e salvar o texto reconhecido, siga estes passos:
- Crie uma instância da classe AsposeOcr.
- Inicialize um objeto da classe DocumentRecognitionSettings.
- Especifique o idioma para OCR.
- Chame o método RecognizePdf() para obter o RecognitionResult.
- Salve o texto usando o método SaveMultipageDocument(), que requer o caminho do arquivo de saída, o SaveFormat e o objeto RecognitionResult.
Aqui está um exemplo demonstrando como fazer OCR em documentos PDF e salvar o texto reconhecido em C#:
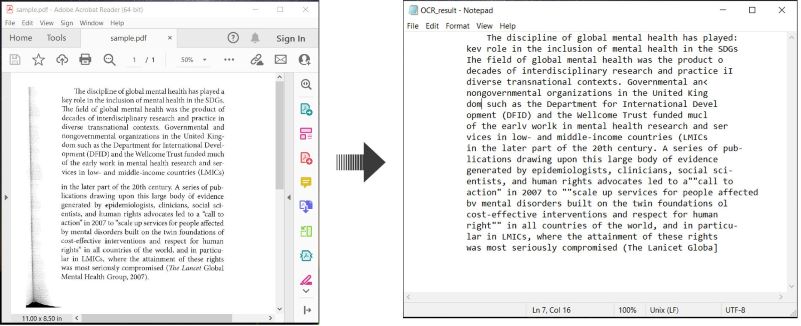
Realizar OCR em PDF e Salvar Texto em C#
Convertendo OCR PDF para Word em C#
Para converter documentos PDF digitalizados para Word, siga os mesmos passos descritos anteriormente, mas especifique SaveFormat.Docx na etapa final.
Aqui está um exemplo ilustrando como fazer OCR em PDF e salvar o texto reconhecido como um documento Word em C#:
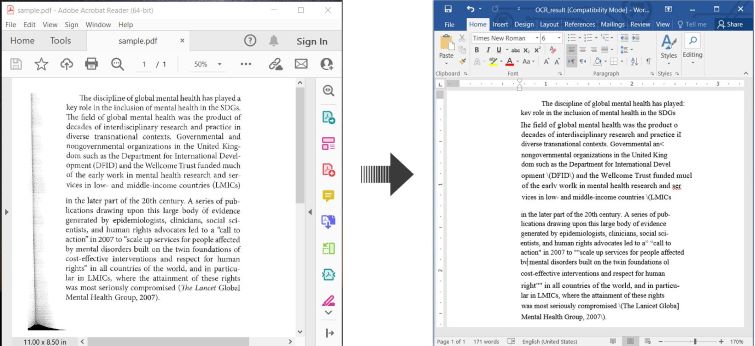
OCR PDF e Converter PDF Digitalizado para Word em C#
Convertendo OCR PDF para JSON em C#
Para salvar o texto reconhecido de documentos PDF em um arquivo JSON, siga os passos anteriores com a única alteração sendo especificar SaveFormat.Json na etapa final.
Aqui está um exemplo demonstrando como fazer OCR em PDF e salvar o texto reconhecido como um arquivo JSON em C#:
Obtenha uma Licença de Avaliação Gratuita
Você pode obter uma licença temporária gratuita para avaliar a Aspose.OCR para API .NET sem quaisquer limitações.
Conclusão
Neste tutorial, aprendemos como realizar OCR em documentos PDF e extrair texto de PDF em C#. Também exploramos como salvar o texto reconhecido como um arquivo TXT, DOCX e JSON. Para mais informações sobre a Aspose.OCR para API .NET, confira sua documentação. Se você tiver alguma dúvida, sinta-se à vontade para entrar em contato conosco em nosso fórum.