
PDF-документы широко используются в бизнесе и часто требуют программного доступа для чтения отсканированного содержимого. Извлечение текста из отсканированных PDF-файлов может быть сложным, поэтому эффективные инструменты необходимы. В этом учебнике мы рассмотрим как выполнять OCR PDF-документы и извлекать текст из PDF на C# с использованием мощного Aspose.OCR для .NET API, первоклассной библиотеки для извлечения текста из PDF на C#, доступной для бесплатной оценки.
Что вы узнаете
В этой статье мы рассмотрим следующие темы:
- Обзор Aspose.OCR для .NET API
- Шаги для OCR PDF и извлечения текста
- Как выполнять OCR на PDF и сохранять текст
- Преобразование OCR PDF в Word
- Преобразование OCR PDF в JSON
Обзор Aspose.OCR для .NET API
Мы будем использовать Aspose.OCR для .NET API, надежное решение OCR PDF для .NET Core. Этот API предназначен для распознавания текста из отсканированных изображений, фотографий со смартфонов и скриншотов, возвращая результаты в различных форматах документов. Он не только преобразует изображения в текст, но также может создавать поисковые PDF из сканов, исправляя орфографические ошибки в распознанном тексте, что делает его одним из самых быстрых решений OCR PDF на C# всего за $99.
API включает класс AsposeOcr, который предоставляет несколько методов для операций OCR. В частности, метод RecognizePdf(string, DocumentRecognitionSettings) используется для извлечения текста из указанного PDF-документа. Класс DocumentRecognitionSettings позволяет настраивать процесс распознавания, в то время как класс RecognitionResult инкапсулирует результаты распознавания.
Вы можете скачать DLL API или установить его через NuGet:
PM> Install-Package Aspose.OCR
Шаги для OCR PDF и извлечения текста на C#
Следуйте этим шагам, чтобы выполнить OCR на PDF-документах и извлечь распознанный текст:
- Создайте экземпляр класса AsposeOcr.
- Инициализируйте объект класса DocumentRecognitionSettings.
- Укажите язык для OCR.
- Получите RecognitionResult, вызвав метод RecognizePdf(), передав путь к изображению и объект DocumentRecognitionSettings.
- Пройдите по списку RecognitionResult, чтобы отобразить распознанный текст.
Вот пример, иллюстрирующий как выполнять OCR PDF-документы и извлекать распознанный текст на C#:
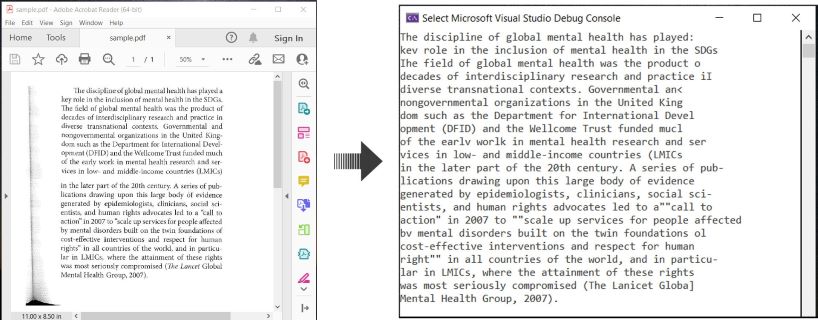
OCR PDF и извлечение текста из PDF на C#
Как выполнять OCR на PDF и сохранять текст на C#
Чтобы выполнить OCR на PDF-документах и сохранить распознанный текст, следуйте этим шагам:
- Создайте экземпляр класса AsposeOcr.
- Инициализируйте объект класса DocumentRecognitionSettings.
- Укажите язык для OCR.
- Вызовите метод RecognizePdf(), чтобы получить RecognitionResult.
- Сохраните текст, используя метод SaveMultipageDocument(), который требует путь к выходному файлу, SaveFormat и объект RecognitionResult.
Вот пример, демонстрирующий как выполнять OCR PDF-документы и сохранять распознанный текст на C#:
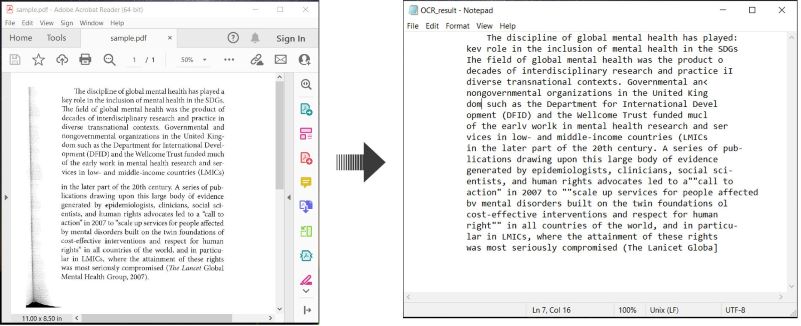
Выполнение OCR на PDF и сохранение текста на C#
Преобразование OCR PDF в Word на C#
Чтобы преобразовать отсканированные PDF-документы в Word, следуйте тем же шагам, что и ранее, но укажите SaveFormat.Docx на последнем шаге.
Вот пример, иллюстрирующий как выполнять OCR PDF и сохранять распознанный текст в виде документа Word на C#:
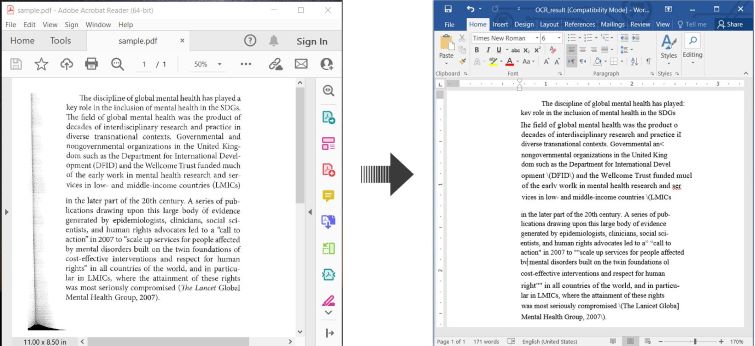
OCR PDF и преобразование отсканированного PDF в Word на C#
Преобразование OCR PDF в JSON на C#
Чтобы сохранить распознанный текст из PDF-документов в JSON-файл, следуйте предыдущим шагам, изменив только последний шаг на указание SaveFormat.Json.
Вот пример, демонстрирующий как выполнять OCR PDF и сохранять распознанный текст в виде JSON-файла на C#:
Получите бесплатную лицензию для оценки
Вы можете получить бесплатную временную лицензию для оценки Aspose.OCR для .NET API без каких-либо ограничений.
Заключение
В этом учебнике мы узнали, как выполнять OCR на PDF-документах и извлекать текст из PDF на C#. Мы также рассмотрели, как сохранить распознанный текст в файлы TXT, DOCX и JSON. Для получения дополнительной информации об Aspose.OCR для .NET API ознакомьтесь с его документацией. Если у вас есть вопросы, не стесняйтесь обращаться к нам на нашем форуме.