
PDF-dokument är allestädes närvarande i affärsverksamhet, och kräver ofta programmatisk åtkomst för att läsa skannat innehåll. Att extrahera text från skannade PDF-filer kan vara komplext, vilket gör effektiva verktyg avgörande. I denna handledning kommer vi att utforska hur man OCR:ar PDF-dokument och extraherar text från PDF i C# med det kraftfulla Aspose.OCR för .NET API, ett förstklassigt C# PDF textextraktionsbibliotek som är tillgängligt för gratis utvärdering.
Vad du kommer att lära dig
I denna artikel kommer vi att täcka följande ämnen:
- Översikt av Aspose.OCR för .NET API
- Steg för att OCR:a PDF och extrahera text
- Hur man utför OCR på PDF och sparar text
- Konvertera OCR PDF till Word
- Konvertera OCR PDF till JSON
Översikt av Aspose.OCR för .NET API
Vi kommer att använda Aspose.OCR för .NET API, en robust .NET Core PDF OCR-lösning. Detta API är utformat för att känna igen text från skannade bilder, mobiltelefonfoton och skärmdumpar, och returnera resultat i olika dokumentformat. Det konverterar inte bara bilder till text, utan kan också skapa sökbara PDF-filer från skanningar samtidigt som det korrigerar stavfel i den igenkända texten, vilket gör det till en av de snabbaste C# PDF OCR-lösningarna som finns tillgängliga för endast $99.
API:et har klassen AsposeOcr som tillhandahåller flera metoder för OCR-operationer. Särskilt används metoden RecognizePdf(string, DocumentRecognitionSettings) för att extrahera text från ett specificerat PDF-dokument. Klassen DocumentRecognitionSettings möjliggör anpassning av igenkänningsprocessen, medan klassen RecognitionResult kapslar in resultaten av igenkänningen.
Du kan ladda ner DLL:en av API:et eller installera den via NuGet:
PM> Install-Package Aspose.OCR
Steg för att OCR:a PDF och extrahera text i C#
Följ dessa steg för att utföra OCR på PDF-dokument och extrahera den igenkända texten:
- Skapa en instans av klassen AsposeOcr.
- Initiera ett objekt av klassen DocumentRecognitionSettings.
- Specificera språket för OCR.
- Skaffa RecognitionResult genom att anropa metoden RecognizePdf(), passera bildvägen och objektet DocumentRecognitionSettings.
- Loop igenom listan RecognitionResult för att visa den identifierade texten.
Här är ett exempel som illustrerar hur man OCR:ar PDF-dokument och extraherar igenkänd text i C#:
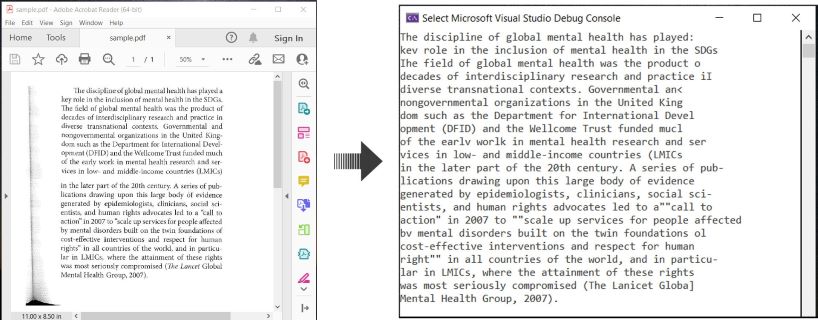
OCR PDF och extrahera text från PDF i C#
Hur man utför OCR på PDF och sparar text i C#
För att utföra OCR på PDF-dokument och spara den igenkända texten, följ dessa steg:
- Skapa en instans av klassen AsposeOcr.
- Initiera ett objekt av klassen DocumentRecognitionSettings.
- Specificera språket för OCR.
- Anropa metoden RecognizePdf() för att få RecognitionResult.
- Spara texten med metoden SaveMultipageDocument(), som kräver utdatafilens sökväg, SaveFormat och objektet RecognitionResult.
Här är ett exempel som demonstrerar hur man OCR:ar PDF-dokument och sparar den igenkända texten i C#:
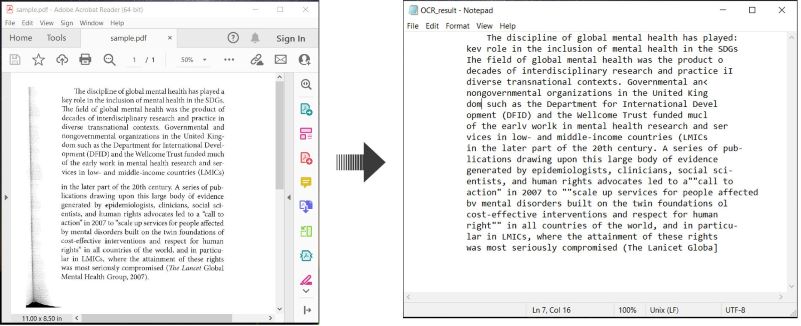
Utför OCR på PDF och spara text i C#
Konvertera OCR PDF till Word i C#
För att konvertera skannade PDF-dokument till Word, följ samma steg som beskrivits tidigare, men specificera SaveFormat.Docx i det sista steget.
Här är ett exempel som illustrerar hur man OCR:ar PDF och sparar den igenkända texten som ett Word-dokument i C#:
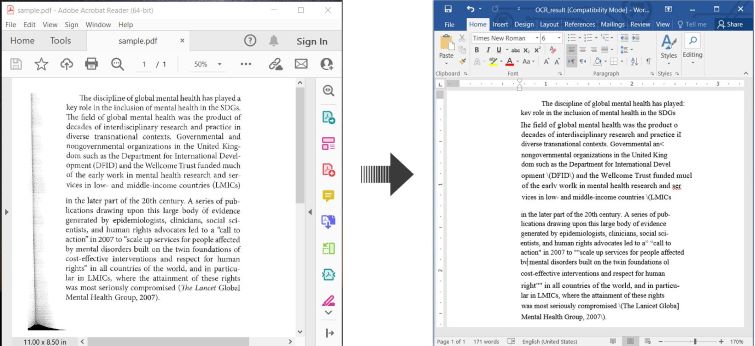
OCR PDF och konvertera skannad PDF till Word i C#
Konvertera OCR PDF till JSON i C#
För att spara den igenkända texten från PDF-dokument i en JSON-fil, följ de tidigare stegen med den enda ändringen att specificera SaveFormat.Json i det sista steget.
Här är ett exempel som demonstrerar hur man OCR:ar PDF och sparar den igenkända texten som en JSON-fil i C#:
Få en gratis utvärderingslicens
Du kan skaffa en gratis temporär licens för att utvärdera Aspose.OCR för .NET API utan några begränsningar.
Slutsats
I denna handledning lärde vi oss hur man utför OCR på PDF-dokument och extraherar text från PDF i C#. Vi utforskade också hur man sparar den igenkända texten som en TXT, DOCX och JSON fil. För mer information om Aspose.OCR för .NET API, kolla in dess dokumentation. Om du har några frågor, tveka inte att kontakta oss på vårt forum.