
PDF文档在商业操作中无处不在,通常需要以编程方式访问以读取扫描的内容。从扫描的PDF文件中提取文本可能很复杂,这就是有效工具至关重要的原因。在本教程中,我们将探讨如何在C#中OCR PDF文档并提取PDF文本,使用强大的Aspose.OCR for .NET API,这是一个可供免费评估的顶级C# PDF文本提取库。
您将学习什么
在本文中,我们将涵盖以下主题:
Aspose.OCR for .NET API概述
我们将利用Aspose.OCR for .NET API,这是一个强大的.NET Core PDF OCR解决方案。该API旨在从扫描的图像、智能手机照片和屏幕截图中识别文本,并以各种文档格式返回结果。它不仅可以将图像转换为文本,还可以从扫描中创建可搜索的PDF,同时纠正识别文本中的拼写错误,使其成为仅需99美元的最快C# PDF OCR解决方案之一。
该API具有AsposeOcr类,提供多个OCR操作的方法。特别是,RecognizePdf(string, DocumentRecognitionSettings)方法用于从指定的PDF文档中提取文本。DocumentRecognitionSettings类允许自定义识别过程,而RecognitionResult类封装识别结果。
PM> Install-Package Aspose.OCR
在C#中OCR PDF并提取文本的步骤
按照以下步骤对PDF文档执行OCR并提取识别的文本:
- 创建AsposeOcr类的实例。
- 初始化DocumentRecognitionSettings类的对象。
- 指定OCR的语言。
- 通过调用RecognizePdf()方法,传递图像路径和DocumentRecognitionSettings对象来获取RecognitionResult。
- 遍历RecognitionResult列表以显示识别的文本。
以下是一个示例,说明如何在C#中OCR PDF文档并提取识别的文本:
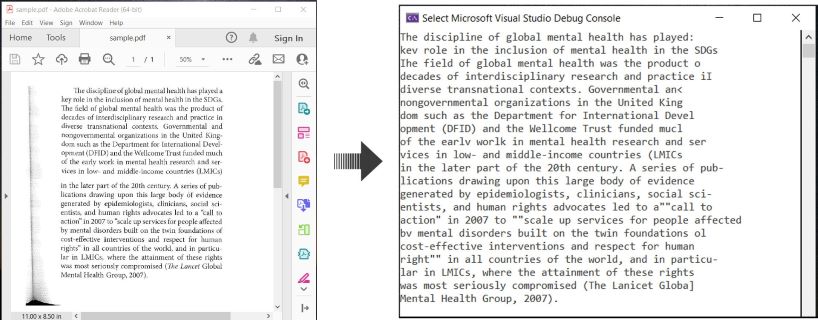
使用C# OCR PDF并提取PDF文本
如何在C#中对PDF执行OCR并保存文本
要对PDF文档执行OCR并保存识别的文本,请按照以下步骤操作:
- 创建AsposeOcr类的实例。
- 初始化DocumentRecognitionSettings类的对象。
- 指定OCR的语言。
- 调用RecognizePdf()方法以获取RecognitionResult。
- 使用**SaveMultipageDocument()**方法保存文本,该方法需要输出文件路径、SaveFormat和RecognitionResult对象。
以下是一个示例,演示如何在C#中OCR PDF文档并保存识别的文本:
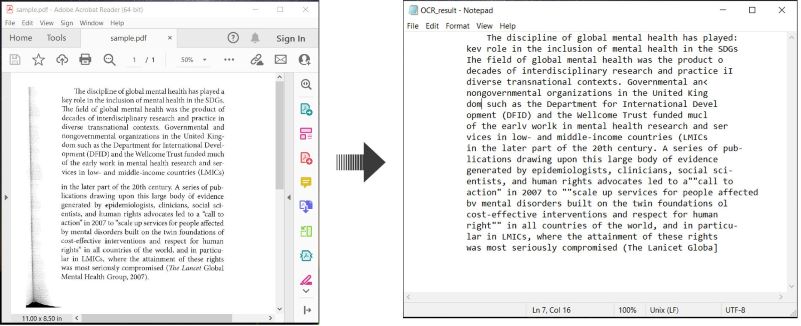
在C#中对PDF执行OCR并保存文本
在C#中将OCR PDF转换为Word
要将扫描的PDF文档转换为Word,请按照之前概述的相同步骤,但在最后一步中指定SaveFormat.Docx。
以下是一个示例,说明如何在C#中OCR PDF并将识别的文本保存为Word文档:
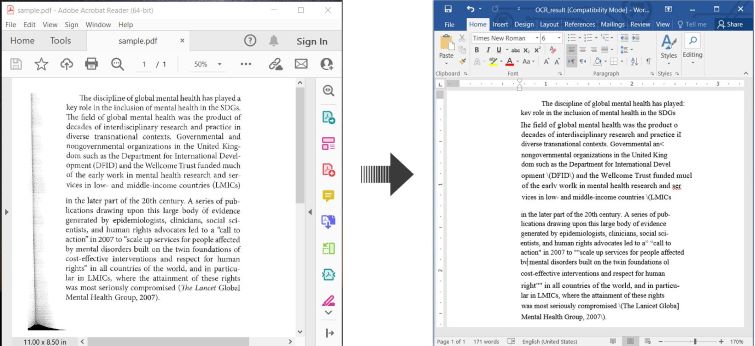
使用C# OCR PDF并将扫描的PDF转换为Word
在C#中将OCR PDF转换为JSON
要将PDF文档中的识别文本保存为JSON文件,请按照之前的步骤进行,唯一的变化是在最后一步中指定SaveFormat.Json。
以下是一个示例,演示如何在C#中OCR PDF并将识别的文本保存为JSON文件:
获取免费评估许可证
您可以获取免费的临时许可证,以在没有任何限制的情况下评估Aspose.OCR for .NET API。
结论
在本教程中,我们学习了如何对PDF文档执行OCR并提取PDF中的文本。我们还探讨了如何将识别的文本保存为TXT、DOCX和JSON文件。有关Aspose.OCR for .NET API的更多信息,请查看其文档。如果您有任何问题,请随时在我们的论坛上与我们联系。