
图像和扫描文档通常包含有价值的文本信息。借助**光学字符识别(OCR)**的强大功能,您可以使用 C# 以编程方式将这些图像转换为可搜索的 PDF 文档。此过程允许您将各种图像格式(包括 JPG、PNG、TIFF 和 BMP)转换为可搜索的 PDF。以下是指导您完成该过程的关键部分:
带 OCR 的图像到可搜索 PDF 转换器 – C# API 安装
为了高效地对图像或扫描文档执行 OCR 操作,您可以使用 Aspose.OCR for .NET API。安装很简单;您可以从 新版本 部分下载 DLL 文件,或通过以下命令通过 NuGet 安装:
PM> Install-Package Aspose.OCR
使用 C# 以编程方式将图像转换为可搜索的 PDF(带 OCR)
按照以下步骤使用 C# 中的 OCR 将 JPG、PNG、TIFF 和其他图像格式转换为可搜索的 PDF:
- 设置要识别的输入图像路径。
- 初始化 AsposeOcr 类的实例。
- 使用 RecognizeImage 方法识别输入图像。
- 将输出保存为可搜索的 PDF 文件。
以下是一个示例代码片段,演示如何使用 C# 将图像转换为可搜索的 PDF:
使用 C# 以编程方式将倾斜图像转换为可搜索的 PDF(带 OCR)
有时,由于各种因素,图像可能会倾斜。如果您知道倾斜角度,可以在识别之前指定它。但是,如果角度未知,API 可以为您计算。按照以下步骤将倾斜图像转换为可搜索的 PDF:
- 指定输入图像的路径。
- 初始化 AsposeOcr 类的实例。
- 创建 RecognitionSettings 类的实例。
- 计算图像的倾斜角度。
- 识别图像并将输出保存为可搜索的 PDF 文件。
以下是如何使用 C# 以编程方式将倾斜图像转换为可搜索的 PDF:
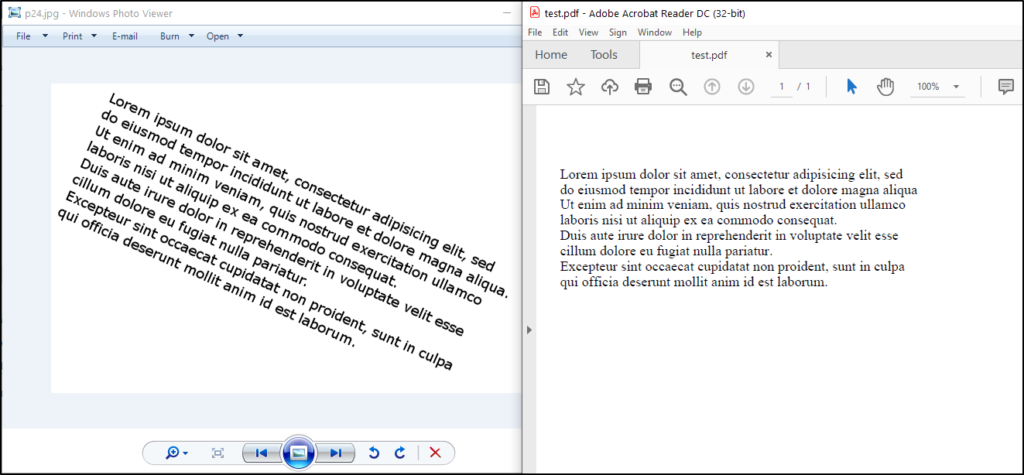
下面是一个截图,展示了输入图像和输出 PDF 文件:
获取免费评估许可证
您可以通过请求 免费临时许可证 来无限制地评估该 API。
结论
在本文中,您学习了如何使用 C# 以编程方式将图像转换为可搜索的 PDF 文件。无论您是在处理 JPG、PNG、BMP、TIFF 还是扫描文档,使用 Aspose.OCR API 的过程都很简单。有关更多功能和详细文档,请访问 文档 部分。如果您有任何问题,请随时通过我们的 免费支持论坛 联系我们。